
TL;DR: Large context windows are powerful, but not enough. If you want AI that’s fast, accurate, and controllable—RAG still matters. Here’s why.
A Quiet Revolution in AI
AI models aren’t just getting smarter—they’re getting way better at remembering.
One of the biggest breakthroughs in 2024 wasn’t raw intelligence. It was memory.
Thanks to massive context windows in models like Claude 4, GPT-4o, and Gemini 2.5, AI can now process the equivalent of an entire book, podcast library, or multi-month email thread in a single interaction.
That’s a big deal.
It means AI can now do things like:
- Review your whole customer journey before replying
- Reference all your past content while helping write new posts
- Understand your business deeply—not just surface-level answers
For creators, founders, and teams using AI to scale…
these huge memory upgrades open up an entirely new playing field.
But here’s the catch:
More memory doesn’t always mean more control.
And that’s exactly where RAG still plays a critical role.
Let’s break it down.
How Context Windows Got Massive—And Why It Matters
Think of a context window like short‑term memory for an AI model—it’s the amount of information the model can “see” and reason over in a single turn.
- Old context windows were tiny—just a few pages.
- Now, models like Claude, Gemini, GPT‑4o, and GPT‑4.1 handle volumes like books, entire websites, or multi-month chat logs.
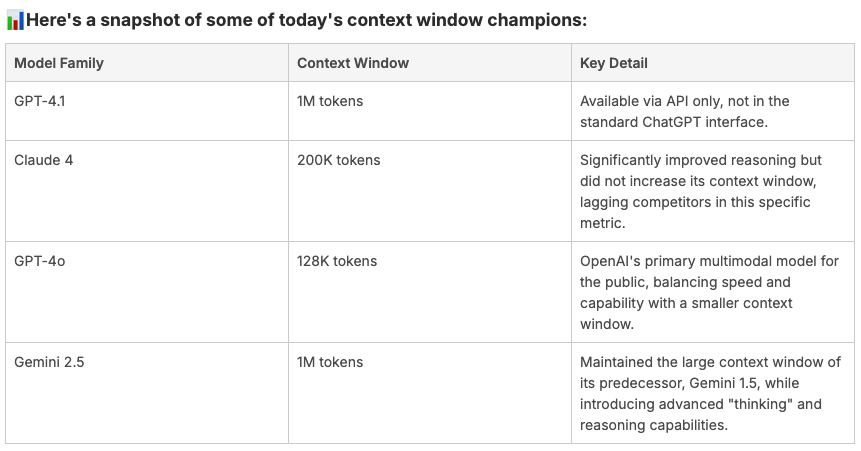
📌 Approximate token-to-page mapping:
- 200K tokens ≈ 500–700 pages
- 128K tokens ≈ 250–400 pages
- 1M tokens ≈ several full-length books
This lets models reason over everything from multi-page support docs to entire codebases or knowledge bases—all at once.
But just because you can load it all in… doesn’t mean you should.
(That’s where RAG still shines.)
Game-Changing Use Cases for Creators & Businesses
Bigger context windows aren’t just a technical flex.
They unlock use cases that were previously out of reach—especially when you want the AI to “just know” a lot without setting up RAG or custom workflows.
